From Java 5 ConcurrentHashMap is introduced as another alternative for HashTable(or explicitly synchronizing the map using synchronizedMap method).
Though we have an option to synchronize the collections like List or Set using synchronizedList() or synchronizedSet() method respectively of the Collections class but there is a drawback of this synchronization; very poor performance as the whole collection is locked and only a single thread can access it at a given time.
On the other hand there is HashTable too which is thread safe but that thread safety is achieved by having all its method as synchronized which again results in poor performance. ConcurrentHashMap in Java tries to address these issues.
Why another Map
First thing that comes to mind is why another map when we already have HashMap or HashTable (if thread safe data structure is required). The answer is better performance though still providing a thread safe alternative. So it can be said that ConcurrentHashMap is a HashMap whose operations are threadsafe.
How performance is improved in ConcurrentHashMap
As I said ConcurrentHashMap is also a hash based map like HashMap, how it differs is the locking strategy used by ConcurrentHashMap. Unlike HashTable (or synchronized HashMap) it doesn't synchronize every method on a common lock. ConcurrentHashMap in Java uses separate lock for separate buckets thus locking only a portion of the Map.
Just for information ConcurrentHashMap uses ReentrantLock for locking.
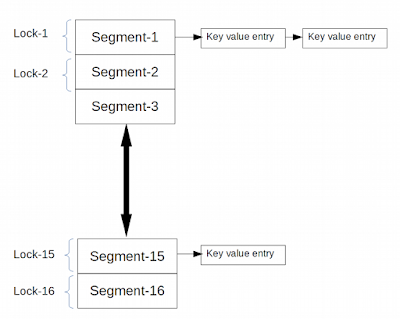
If you have idea about the internal implementation of the HashMap you must be knowing that by default there are 16 buckets. Same concept is used in ConcurrentHashMap and by default there are 16 buckets and also separate locks for separate buckets. So the default concurrency level is 16.
Which is effectively this constructor
This constructor creates a new, empty map with a default initial capacity (16), load factor (0.75) and concurrencyLevel (16).
ConcurrentHashMap()
There are several other constructors, one of them is
ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel)
Creates a new, empty map with the specified initial capacity, load factor and concurrency level. So, using this constructor you can provide your own initial capacity (default is 16), own load factor and also concurrency level (Which by default is 16).
Since there are 16 buckets having separate locks of their own which effectively means at any given time 16 threads can operate on the map concurrently, provided all these threads are operating on separate buckets.
So you see how ConcurrentHashMap provides better performance by locking only the portion of the map rather than blocking the whole map resulting in greater shared access.
Further performance improvement in ConcurrentHashMap
That is not all, performance is further improved by providing read access concurrently without any blocking. Retrieval operations (including get) generally do not block, so may overlap with update operations (including put and remove). Retrievals reflect the results of the most recently completed update operations which may mean that retrieval operations may not fetch the current/in-progress value (Which is one drawback). Memory visibility for the read operations is ensured by volatile reads. You can see in the ConcurrentHashMap code that the val and next fields of Node are volatile.
Also for aggregate operations such as putAll and clear which works on the whole map, concurrent retrievals may reflect insertion or removal of only some entries (another drawback of separate locking). Because read operations are not blocking but some of the writes (which are on the same bucket) may still be blocking.
Simple example using ConcurrentHashMap
At this juncture let's see a simple example of ConcurrentHashMap in Java.
public class CHMDemo {
public static void main(String[] args) {
// Creating ConcurrentHashMap
Map<String, String> cityTemperatureMap = new ConcurrentHashMap<String, String>();
// Storing elements
cityTemperatureMap.put("Delhi", "24");
cityTemperatureMap.put("Mumbai", "32");
//cityTemperatureMap.put(null, "26");
cityTemperatureMap.put("Chennai", "35");
cityTemperatureMap.put("Bangalore", "22" );
for (Map.Entry e : cityTemperatureMap.entrySet()) {
System.out.println(e.getKey() + " = " + e.getValue());
}
}
}
Null is not allowed
Though HashMap allows one null as key but ConcurrentHashMap in Java doesn't allow null as key. In the previous example you can uncomment the line which has null key. While trying to execute the program it will throw null pointer exception.
Exception in thread "main" java.lang.NullPointerException
at java.util.concurrent.ConcurrentHashMap.putVal(Unknown Source)
at java.util.concurrent.ConcurrentHashMap.put(Unknown Source)
at org.netjs.prog.CHMDemo.main(CHMDemo.java:16)
Atomic operations
ConcurrentHashMap in Java provides a lot of atomic methods, let's see it with an example how these atomic methods help. Note that from Java 8 many new atomic methods are added.
Suppose you have a word Map that counts the frequency of every word where key is the word and count is the value, in a multi-threaded environment, even if ConcurrentHashMap is used, there may be a problem as described in the code snippet.
public class CHMAtomicDemo {
public static void main(String[] args) {
ConcurrentHashMap<String, Integer> wordMap = new ConcurrentHashMap<>();
..
..
// Suppose one thread is interrupted after this line and
// another thread starts execution
Integer prevValue = wordMap.get(word);
Integer newValue = (prevValue == null ? 1 : prevValue + 1);
// Here the value may not be correct after the execution of
// both threads
wordMap.put(word, newValue);
}
}
To avoid these kind of problems you can use atomic method, one of the atomic method is compute which can be used here.
wordMap.compute(word, (k,v)-> v == null ? 1 : v + 1);
If you see the general structure of the Compute method
Here BiFunction functional interface is used which can be implemented as a lambda expression.
compute(K key, BiFunction<? super K,? super V,? extendsV> remappingFunction)
So here rather than having these lines -
you can have only this line
Integer prevValue = wordMap.get(word);
Integer newValue = (prevValue == null ? 1 : prevValue + 1);
wordMap.put(word, newValue);
wordMap.compute(word, (k,v)-> v == null ? 1 : v + 1);
The entire method invocation is performed atomically. Some attempted update operations on this map by other threads may be blocked while computation is in progress.
There are several other atomic operations like computeIfAbsent, computeIfPresent, merge, putIfAbsent.
Fail-safe iterator
Iterator provided by the ConcurrentHashMap is fail-safe which means it will not throw ConcurrentModificationException.
Example code
public class CHMDemo {
public static void main(String[] args) {
// Creating ConcurrentHashMap
Map<String, String> cityTemperatureMap = new ConcurrentHashMap<String, String>();
// Storing elements
cityTemperatureMap.put("Delhi", "24");
cityTemperatureMap.put("Mumbai", "32");
cityTemperatureMap.put("Chennai", "35");
cityTemperatureMap.put("Bangalore", "22" );
Iterator<String> iterator = cityTemperatureMap.keySet().iterator();
while (iterator.hasNext()){
System.out.println(cityTemperatureMap.get(iterator.next()));
// adding new value, it won't throw error
cityTemperatureMap.put("Kolkata", "34");
}
}
}
Output
24
35
34
32
22
According to the JavaDocs - The view's iterator is a "weakly consistent" iterator that will never throw ConcurrentModificationException, and guarantees to traverse elements as they existed upon construction of the iterator, and may (but is not guaranteed to) reflect any modifications subsequent to construction.
When ConcurrentHashMap is a better choice
ConcurrentHashMap is a better choice when there are more reads than writes. As mentioned above retrieval operations are non-blocking so many concurrent threads can read without any performance problem. If there are more writes and that too many threads operating on the same segment then the threads will block which will deteriorate the performance.
Points to note
- ConcurrentHashMap is also a hash based map like HashMap, but ConcurrentHashMap is thread safe.
- In ConcurrentHashMap thread safety is ensured by having separate locks for separate buckets, resulting in better performance.
- By default the bucket size is 16 and the concurrency level is also 16.
- No null keys are allowed in ConcurrentHashMap.
- Iterator provided by the ConcurrentHashMap is fail-safe, which means it will not throw ConcurrentModificationException.
- Retrieval operations (like get) don't block so may overlap with update operations (including put and remove).
That's all for this topic ConcurrentHashMap in Java. If you have any doubt or any suggestions to make please drop a comment. Thanks!
Related Topics
You may also like -